Мне пришла в голову система организации оперативной или постоянной памяти, которуя я назвал ленточной. Система настолько очевидна, что мне кажется, ее уже придумали, но на пути ее реализации есть какие-то препятствия. Буду благодарен, если мне объяснят, что я опять изобрел велосипед. Но если все-таки я придумал полезную для общества вещь, надеюсь, предприниматели, которые обогатятся на этом изобретении, пожертвуют мне средства на мою мечту – трехкомнатный дом в г.Калининграде.
Новый вид памяти позиционируется мною в основном или как постоянная память ПЗУ (аналог записанных CD-дисков) или как оперативная память для мультимедийных устройств (видеокамеры, цифровые аппараты и т.п.). Ее ближайший собрат - флеш память и преимущества точно такие же - отсутствие движущихся и механических деталей, простота изготовления и гораздо более дешевая чем у флеш-памяти цена.
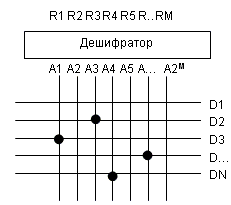
Для начала рассмотрим недостатки существующей памяти, реализуемой на микросхемах. Обычная память c адресом из M разрядов и данными из N разрядов имеет вот такое устройство:
Дешифратор расшифровывает адрес - т.е. для М-разрядного адреса R он выдает бит на тот вход A, адресу которого соответствует адрес R. Данные считываются с выходов D. Очевидный недостаток - большое число пересекающихся линий, из-за чего схему приходится дробить на блоки, чтобы M было как можно меньше.
Ленточная память
Я предлагаю избавиться от недостатка большого числа линий обыкновенной памяти, предлагая организовать ЛЕНТОЧНУЮ ПАМЯТЬ:
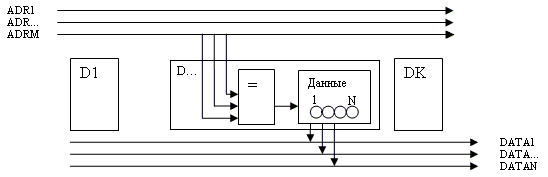
Здесь схема памяти, которая имеет всегда фиксированное число шин, независимо от разрядности адреса - а именно M шин адреса ADR и N шин данных DATA. Адрес поступает с шины адреса на сравнитель каждой ячейки, который выдает 1, если на шину выставлен адрес текущей ячейки и ноль, если адрес не совпадает. Если адрес совпадает, тогда данные из N ячеек памяти передаются на выходную шину DATA.
Такую память можно скрутить в катушку или наматывать слой за слоем, шины каждого слоя подключая параллельно, чтобы если произошел обрыв шины в одном слое, шины других слоев не пострадали. Получается очень надежная и простая память.
По сравнению с обычной памятью кроме N битов для хранения данных еще используется сравнитель адреса из M фиксированных побитных сравнителей (адрес ячейки всегда постоянный). Таким образом за счет добавления М сравнителей в каждую N-разрядную ячейку памяти мы укорачиваем шину адреса с 2 в степени M до всего лишь M разрядов и вся память представляет собой одну большую цепочку - ленту. Возможно этот вариант более дешевый и простой, чем первый.
Также возможна передача сигнала NEXT следующей ячейке для потокового чтения данных (экономится один такт на сравнение адреса).
Усложненная схема (меньше шин)
Очевидно, что первый вариант ленточной памяти самый эффективный, однако ради академического интереса рассмотрим дальнейшие способы сокращения шин адреса и данных.
На следующей схеме всего одна линия адреса вне зависимости от
разрядности адреса. Адрес передается последовательно, бит за битом по шине ADR.
Все ячейки данных воспринимают этот адрес и как только обнаружено совпадение,
начинают выдавать данные тоже последовательно на шину DATA. После того, как
выдан последний бит, генерируется сигнал NEXT для следующей ячейки и уже она
начинает выдавать данные на шину DATA.
Сигнал RUN служит для указания, что начинается передача адреса.
Сигнал SYNC существует во всех электронных схемах и служит для синхронизации
по времени всех ячеек.
Аналогично и при записи - выставляется адрес, затем последовательно передаются
данные. Очевидно, при записи нужно еще указывать момент начала передачи данных.
Или же он будет равен следующему такту после передачи последнего бита адреса.
После записи данных в ячейку запись ведется в следующую ячейку и т.п.

Такая схема очень удобна для последовательных данных - потока музыки, видео
и т.п.
Если это ПЗУ, то питание можно подавать только на момент считывания данных,
включая для инициализации сигнал RUN.
Все блоки данных имеют одинаковое устройство (за исключением адреса - он уникальный
для каждой ячейки), т.е. можно печатать на плате основные шины и припечатывать
к ним одинаковые блоки с вариациями в сравнителях адреса.
При получении сигнала начала обработки RUN или сигнала NEXT,
схема ячейки памяти инициализируется. Т.е. признак соответствия адресу ME устанавливается
равным 1, сигнал сравнения адреса передается первому сравнителю адреса.
Далее при получении каждого бита адреса срабатывает текущий сравнитель адреса.
Если результат сравнения – ложь, то ME устанавливается в 0 и схема больше не
работает до получения следующего RUN.
Если все сравнители адреса отработали, передается сигнал выдачи первому генератору
данных. Он выдает бит хранимых данных на шину DATA и передает сигнал выдачи
следующему генератору данных. Последний генератор данных после выдачи данных
передает сигнал NEXT следующей ячейке памяти.
Схема достаточно проста. У нее только один триггер с памятью ME. Все сравнители адреса - без памяти, прошиты непосредственно в микросхеме. Генераторы данных - обычные логические элементы без памяти. В принципе, схема должна стоить достаточно дешево.
Вариации ленточной памяти
Ради интереса я рассмотрел еще несколько схем.
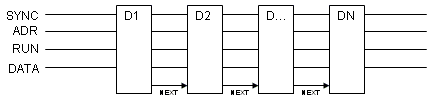
Схема, где общие шины вообще отсутствуют - сигнал передается
от ячейки к ячейке. Начальный адрес ищется долго и данные передаются долго,
но после того, как они начали передаваться, поток идет непрерывно. Т.е. начальное
позиционирование долгое, зато выдача постоянна.
Например для постоянной памяти с музыкой с битрейдом 128 кБит/секунду можно
организовать 128К таких линий, тогда длина цепочки будет соответствовать длине
произведения в секундах и в принципе, позиционироваться достаточно быстро.
Но возможны и не такие экстремальные схемы. Например такая:
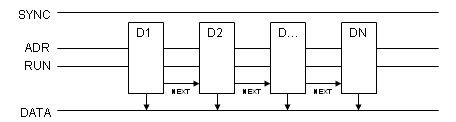
Начальное позиционирование опять же долгое, но данные выдаются сразу на шину DATA.
Необычные применения
Т.к. адрес анализируется сразу всеми ячейками, очень удобно применять ленточную память для ассоциативной памяти. Т.е. на вход подается не адрес, а ключ. Ячейка сохраняет ключ, затем сохраняет значение. При запросе на чтение ячейкам передается ключ, они сравнивают его с хранимым ключом и выдают значение.
Или же можно использовать эту схему для быстрой навигации в списках неопределенной длины. Ячейка хранит идентификатор списка и номер позиции внутри списка. Так как отрабатывают все ячейки сразу, то позиция в списке находится за один проход.